Team Nov 02, 2022 No Comments
Data engineering is among the most in-demand career options presently and a highly profitable one at that. And if you are thinking about what data engineering holds, what will be the growth pathway, or how to become a data engineer, then you are at the right place. In this article, we are going to have a look at some of the most effective data engineering tips that you can imbibe for a better data engineering career option.
Data engineers basically create reservoirs for storing data and also take care of these reservoirs. They are generally guardians of the data which is available to companies. They manage all our personal data and also preserve it. They help in making sufficient unorganized data into data that can be used so that business analysts and also data scientists can anticipate it.
A data engineer basically arranges datasets as per the requirement of the industry. They test, construct, and maintain the primary database mechanism. They are also responsible for creating algorithms for converting data into useful structures and formulating the latest data analytics tools. Data engineers collaborate with management teams to know the aim of the company.

As stated above, data engineering is an interdisciplinary profession that needs a mixture of technical and also business knowledge to create the most impact. Beginning a career in data engineering, it is not always clear what is important to be successful. So these data engineering tips will help you in navigating your career better.
There are five primary tips that we would recommend to any data engineer who is just starting their career.
Skill is the key. It opens avenues to many new chances. Skills are required for every job role and one needs to learn the skill sets that are needed so that one can have a roadmap of what that specific job entails. The below-mentioned skills are needed to be a successful data engineer.
Coding is an important skill you need to work with data on a bigger scale. Python is one of the most used languages to master data science. Along with Python, you can also master Java, Scala, and many more. These are crucial for analysis.
As a data engineer, you will basically be needing to function with databases, constructing, handling, and extracting data from databases. These are basically two types of databases (DBMS) that you will work with:
Moving data from several sources of data to a single database is a part of the ETL process. By using these technologies, data can be converted into valuable data.
The ETL process involves transferring data from various sources of data to a single database. These technologies allow data to be transformed into useful data.
It’s excellent to know how to save data, but you should also be familiar with online data storage. Data is stored online using cloud computing to boost accessibility.
It helps to have a foundational understanding of machine learning. Although it is not directly related to data engineers, machine learning aids them in understanding the requirements of a data scientist.
Data engineers, like those in every other profession, must frequently communicate with a variety of people, including business analysts, data scientists, and other data engineers.
Your skills can be validated with a certificate. It gives the potential employer a sense of your abilities and experience. You can choose from a number of reputable platforms for accredited courses. You can choose professional courses and one best in the industry is from Ivy Professional School.
A certificate can be used to verify your abilities. It provides the prospective employer with information about your skills and experience. For authorized courses, you have a variety of trustworthy sites to pick from. Create a solid portfolio, do industry-level projects, and get into case studies that will help you to a great extent.
Once you get a job, you will know that data engineering is a growing career. You should keep in mind nevertheless that learning doesn’t end here. Working with data requires ongoing learning and development. Languages are constantly evolving, so it’s important to stay up with these changes if you want to advance as a data engineer. Join or start a group that focuses on data engineering and associated skills so that everyone in the community can contribute their thoughts and continue to hone their abilities.
Using your Linkedin profile, you can get in touch with various businesses or work for yourself. Share your resume with them, ask them to provide you with some work, and show your want to work for the organization and team. Your college career and confidence will grow if you work on beginner-level assignments. Extrovert yourself. Make friends with others. Every day, acquire new knowledge. You will benefit from having an internship in your early career.
Working on tasks at the introductory level will advance your academic career and confidence. Be outgoing yourself. Make new acquaintances. Learn something new every day. You will benefit from having an internship in your early career. Such a large amount of data requires laborious management. Industries can manage their data effectively thanks to data engineers. It is simple for you to find employment in this industry if you have the necessary talents and follow all the above-mentioned data engineering tips, such as coding, data storage, cloud storage, etc. Obtaining a legitimate certificate will elevate your profile.
Team Sep 13, 2022 No Comments

Updated in May, 2024
Do you know Netflix and Spotify use the Scikit-learn library for content recommendations?
Scikit-learn is a powerful machine learning library in Python that’s primarily used for predictive analytics tasks such as classification and regression.
If you are a Python programmer or aspiring data scientist, you must master this library in depth. It will help you with projects like building content-based recommendation systems, predicting stock prices, analyzing customer behavior, etc.
In this blog post, we will explain what is Scikit-learn and what it is used for. So, let’s get started…
Scikit-learn is an open-source library in Python that helps us implement machine learning models. This library provides a collection of handy tools like regression and classification to simplify complex machine learning problems.
For programmers, AI professionals, and data scientists, Scikit-learn is a lifesaver. The library has a range of algorithms for different tasks, so you can easily find the right tool for your problem.
Now, there is often a slight confusion between “Sklearn” and “Scikit-learn.” Remember, both terms refer to the same thing: an efficient Python library.
Although Scikit-learn is specifically designed to build machine learning models, it’s not the best choice for tasks like data manipulation, reading, or summary generation.
Scikit-learn is built on the following Python libraries:
Scikit-learn was developed with real-world problems in mind. It’s user-friendly with a simple and intuitive interface. It improves your code quality, making it more robust and optimizing the speed.
Besides, the Scikit-learn community is supportive. With a massive user base and great documentation, you can learn from others and get help when you need it. You can discuss code, ask questions, and collaborate with developers.
Scikit-learn was created by David Cournapeau as a “Google Summer Of Code” project in 2007. It quickly caught the attention of the Python scientific computing community, with others joining to build the framework.
Since it was one of many extensions built on top of the core SciPy library, it was called “scikits.learn.”
Matthieu Brucher joined the project later, and he began to use it as a part of his own thesis work.
Then, in 2010, INRIA stepped in for a major turning point. They took the lead and released the first public version of Scikit-learn.
Since then, its popularity has exploded. A dedicated international community drives its development, with frequent new releases that improve functionality and add cutting-edge algorithms.
Scikit-learn development and maintenance is currently supported by major organizations like Microsoft, Nvidia, INRIA foundation, Chanel, etc.
The Scikit-learn library has become the de facto standard for ML (Machine Learning) implementations thanks to its comparatively easy-to-use API and supportive community. Here are some of the primary uses of Scikit-learn:
Here’s a small example of how Scikit-learn is used in Python for Logistic Regression:
from sklearn.linear_model import LogisticRegression; model = LogisticRegression().fit(X_train, y_train)
Explanation:
Now, you must have understood what is Scikit-learn in Python and what it is used for. Scikit-learn is a versatile Python library that is widely used for various machine learning tasks. Its simplicity and efficiency make it a valuable tool for beginners and professionals.
If you want to learn machine learning with the Scikit-learn library, you can join Ivy’s Data Science with Machine Learning and AI certification course.
This online course teaches everything from data analytics, data visualization, and machine learning to Gen AI in 45 weeks with 50+ real-life projects.
The course is made in partnership with E&ICT Academy IIT Guwahati, IBM, and NASSCOM to create effective and up-to-date learning programs.
Since 2008, Ivy has trained over 29,000+ students who are currently working in over 400 organizations, driving the technology revolution. If you want to be the next one, visit this page to learn more about Ivy’s Data Science with ML and AI Certification course.
Team Sep 01, 2022 No Comments
In the present scenario, data is the basis of virtually every association. Companies in the current market scenario produced a prominent quantity of the 79 zettabytes of big data anticipated by Statista and hence are responsible for the big share of its usage, storage, and processing. Data analytics frameworks are crucial to all large-scale data management and optimization efforts.
These frameworks combine effective processes with cutting-edge data technologies to formulate insight and effective strategies for the operations of the companies. Traditional models did not look at the requirements of the companies as a whole, hence playing with data and creating roadblocks to efficiency. Evaluating modern data analytics frameworks and imposing them successfully will be important for any business aiming to move ahead of the graph.
The data analytics framework in data analytics is a concrete mechanism for handling data analytics effectively and efficiently. But the term itself is used in various ways. At times, these illustrate data analytics frameworks. Will be talking about the whole process and also the best practices for handling data analytics. Major data analytics framework examples include, Sample, Model, and Assess (SEMMA), Explore, Modify, process, and the Cross-Industry Standard Process Data Mining (CRISP-DM) guidelines. In other scenarios, the phrase is used in connection with data analytics solutions such as Teradata Vantage, as well as burgeoning data trends like the data mesh design pattern.
In the case of practicals, think of data analytics frameworks as an amalgamation of technologies and processes. The prominent guidelines and also the solutions used will differ often broadly among companies. But the fundamental aim of data analytics frameworks is consistent and that is to help enterprises utilize analytics in a way that derives the the greatest possible value from the data. The scarcity of such a framework, and taking a piecemeal, disorganised strategy of data analysis is a choice in the present-day business world.
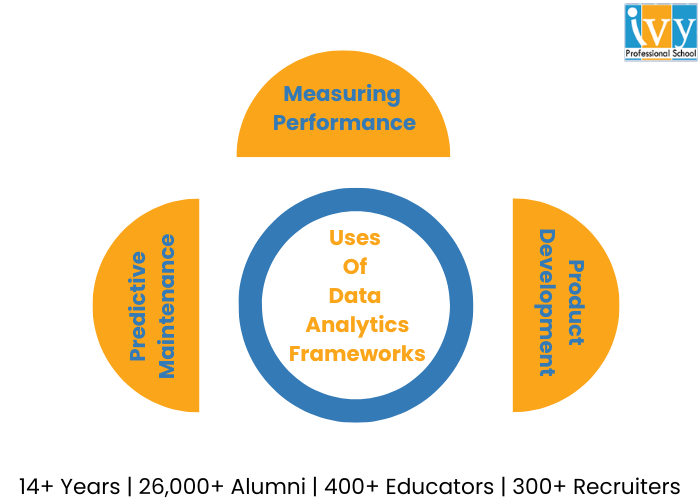
Companies typically base their data analytics frameworks on a clearly defined purpose. The aim of the basic data analytics framework can be initially something like “What business outcomes do we hope to achieve for our enterprise with data analytics?”. From there data teams are divided into different branches for more prominent operations.
This is among the most commonly used scenarios for analytics and the frameworks supporting them. Companies are required to be consistently cognizant of everything that impacts their bottom line and gathering KPI (key performance indicators) and evaluating them is how they maintain awareness.
A data analytics framework offers data teams processes and also tools for broad-ranging performance assessment. For example profitability across varied business units along with its narrower operations such as keeping track of customer facing applications regulating users, engagement, and also new user adoption.
Presently, it is impossible to develop a new item in a vacuum. Development must be informed by data that include historical sales figures, KPIs related to the success or failure of the competitor with a similar product or service, demand analysis, projections of potential product failures, and many more.
The ability of various modern devices ranging from smartphones and medical wearables to modern cars to collect consumer behaviour data adds another dimension of insight developers can draw upon. Data analytics frameworks assure that product teams can take advantage of the last mistakes and determine better product design strategies for the future.
With this framework in place, manufacturers and other heavy industrial businesses can evaluate machine health, anticipate the likelihood of failure, and schedule priority repairs when required. This helps to minimize equipment downtime and keep production schedules on track. These frameworks of data analytics offer the structure analysts need to gather all the information crucial to making these anticipations such as a number of previous repairs, equipment age, indicators to wear and tear overall effectiveness, and many more.
To attain optimal results by using any data analysis framework, support cutting-edge technologies and also solutions:
1. Given that modern enterprise data management is predominantly driven by cloud trends, your framework should already be cloud-ready but without sacrificing your on-premise data infrastructure.
2. The hybrid multi-cloud deployment will offer you the most flexibility in this respect, specifically if the analytic requirements of your organisation include real-time stream processing.
3. Also, data integration from all relevant sources is very crucial and the solution and also the tools you utilize as a part of your structure should support this.
4. An analytics channel with warehousing potential, for instance, can offer an effective foundation for integration.
5. Utilizing object storage infrastructure to formulate a data lake that operates along with a data warehouse assures that all structured, unstructured, and semi-structured data can be categorized and formatted properly for later analysis and processing.
With that let us have a look at some of the best frameworks for data analytics for this year.
This is an end-to-end ML (Machine Learning) platform that features a comprehensive, flexible framework of elements and also libraries along with community resources, allowing one to construct applications that are powered by ML more conveniently. It also makes it more convenient to integrate data such as graphs, SQL tables, images all together. This was first formulated by Google Brain Team and to this day this remains completely open-source.
Scikit-learn is an open-source ML library that is used in the Python programming language, featuring several classifications, clustering, and regression algorithms. It is created for incorporating numericals and scientific libraries such as NumPy and SciPy, both of which are used and developed in Python.
Keras is a famous open source software library that has the potential to operate atop other libraries such as TensorFlow, CNTK, and Theano. With ample data, you can paddle in AI and Deep Learning over this framework.
A data manipulation and analysis language that is written in Python and for Python provides operations and data structures for manipulating NumPy based time series and dates. It is employed to normalise messy and incomplete data with features of slicing, shaping, merging, and dicing datasets.
A library with avid support for Java, Python, Scala, and R, this data analytics framework can be utilised on Hadoop, Kubernetes, Apache Mesos, over cloud services that deal with several data sources.
If you successfully deploy a data analytics framework based on sound principles of data science and are supported by reliable, agile technologies, your company has the ability to identify various advantages. Here are some of the most notable advantages of data analytics frameworks.
A cloud-centric analytics framework enables the coexistence of multiple types of data and permits several methods of analytics. Together, it helps prominently speed up the integration and efficient use of data, cutting down on time to evaluate and minimizing performance bottlenecks.
Hence, less time is spent on preparing, processing, and also reconfiguring data implying more time can be devoted to using data in innovative ways. The speed of integration and use also enables real-time data processing. This can enhance customer service, boost more efficient internal collaboration and innovation, and facilitate operational efficiency.
Using a cutting-edge, cloud-based data analytics framework offers your company the potential to store, access, and utilize all your data without reformatting, duplicating, or moving it around. Instead of having data spread out and in various incompatible formats, you can enter straight into analytics, innovations, and applications. This finally, will support an end-to-end view of the business and formulate an SSOT (Single Source Of Truth).
In an unpredictable business scenario when the customer demands and the requirements of the organization can alter immediately, a data analytics framework that enables you to boost on a dime is invaluable. That is exactly what you get with a cloud framework. This scalability can also boost cost savings. The tools that are utilized in more traditional analytics frameworks can be quite expensive and include rigid pricing structures, but cloud analytics solutions enable you to pay only for what you see.
There are various strategies for business analytics and numerous tools that support them, and the industry will evolve wider in the near future. Instances of key trends to watch include:
1. The sector for self-servicing reporting prevails to expand as more business users grow their inclination towards taking advantage of analytics without requiring the expertise of a data scientist, engineer, or analyst.
2. Deep learning, which is the advanced form of ML (Machine Learning) based on a multi-layer neural network, will slowly increase as more companies attain the resources required to support their computations.
3. Researchers anticipate the adoption of data fabric ideas to increase because of rising interest in real-time streaming analytics.
Data teams should keep a track of these and other developments and evaluate whether they should adopt their data analytics frameworks and architectures to accommodate them.
Data analytics frameworks are crucial to all large-scale data management and optimization efforts. These frameworks combine effective processes with cutting-edge data technologies to formulate insight and effective strategies for the operations of the companies.
The 5 types of data analytics include Descriptive Analytics, Diagnostic Analytics, Predictive Analytics, Prescriptive Analytics, and Cognitive Analytics.
The top 3 best data analytics framework types include TensorFlow, Scikit-learn, and Keras.